
Large Language Epistemology
Do LLMs know anything? And what does that tell us about their reliability as a guide to truth?

This article is a written version of a presentation I gave at a workshop that sought explicit feedback. This means that it is noticeably longer than most of my posts. I intend to publish a follow up that reflects on the feedback in the workshop and any comments I get here.
Modern AI systems, and particularly Large Language Models (LLMs) like ChatGPT, behave in very human ways - including in the way they make assertions about facts and the nature of the world. Given the way people increasingly rely on these systems for information, it raises the question of whether LLMs actually know what they are talking about. Or to put it a bit differently, when can we trust them for reliable or true information?
If we are talking about humans, these are both variants of the same question. And given their human-like behaviours, it is easy to treat LLMs as if they are human and function in very similar ways. However, this misses notable differences between human intelligence and the type of artificial intelligence exhibited by LLMs. This means we should pay attention to how LLMs 'know' the information they provide and where this is different to human knowledge. This provides useful insights about when, and how, we should trust them.
LLMs and traditional epistemology
There are two distinct models of a trustworthy source of information that we are all familiar with: one is exemplified by a textbook (or any similar reference source) and another by a person. For a textbook, while we would never say that it knows anything, we would still trust the information it provides, especially if it is from a reputable brand or author. On the other hand, we do not trust what a person tells us if they do not know what they are talking about. Do LLMs fit either of these two models?
For a start, they clearly do not fit the model of a textbook. For books, our trust in their content is entirely contingent on our trust of the authors. Whether we think the book gives us reliable information depends on whether the authors know what they are talking about. LLMs, however, draw on a huge range of information sources and do their own analysis on that information - so there is no set of authors to directly draw on for reliability. In this sense, they are more like people who draw on information from many sources and analyse it themselves. However, does the human model work for an LLM? Can we say that they know what they are talking about?
The traditional starting point in philosophy for thinking about the nature of knowledge has been that knowledge is, at its core, a Justified True Belief. That is: a person A knows P if, and only if:
A believes P,
P is true, and
A’s belief that P is justified.
While there are a range of reasons why this fails to hold up as a tight definition, it is a very useful starting point. To summarise a vast literature, when we think about human knowledge and this definition, all the major questions revolve around truth, justification and the connection between them. However, it is different with AI.
A human cannot know something if they do not believe it. This is because it is entirely possible to have some true information in your head, and have justification for thinking it is true, but not actually believe it to be true. In that case, a human clearly doesn't know it, because they don't take it to be true.
But does this hold for AI systems? Does an LLM actually have beliefs? Does an LLM believe that some things are the case and others aren't? While they provide us with assertions about the world that read like human belief statements, it is, at best, unclear that these constitute substantial beliefs about the world.1 A good example is the way that they will concede that the information they have provided is incorrect when challenged. A person with substantial beliefs will defend their beliefs, but LLMs usually just provide us with different information.
So it seems like a stretch to say that LLMs know what they are talking about in the traditional sense of the word, as they do not have strong beliefs. However, that doesn't necessarily undermine their usefulness or reliability as providers of information - particularly as this is what we often look to LLMs for. A text book clearly doesn't know anything itself, but that doesn't matter if we can trust the information it includes is true.
This means that we have to pay attention to how LLMs work to help us decide whether and when we should treat them as reliable - especially as they don't fit either the model of a person or of a textbook. One efficient way to do this is to contrast them with humans and how we build reliable information and truths (i.e. knowledge). To summarise the arguments I've made elsewhere, humans do this through an ongoing process of testing what we think to be the case (i.e. what we believe) against experiences and reality. What we think to be the case are theories, principles, stories, pictures and other representations of the world. The whole process works as a continual learning loop that looks something like this:
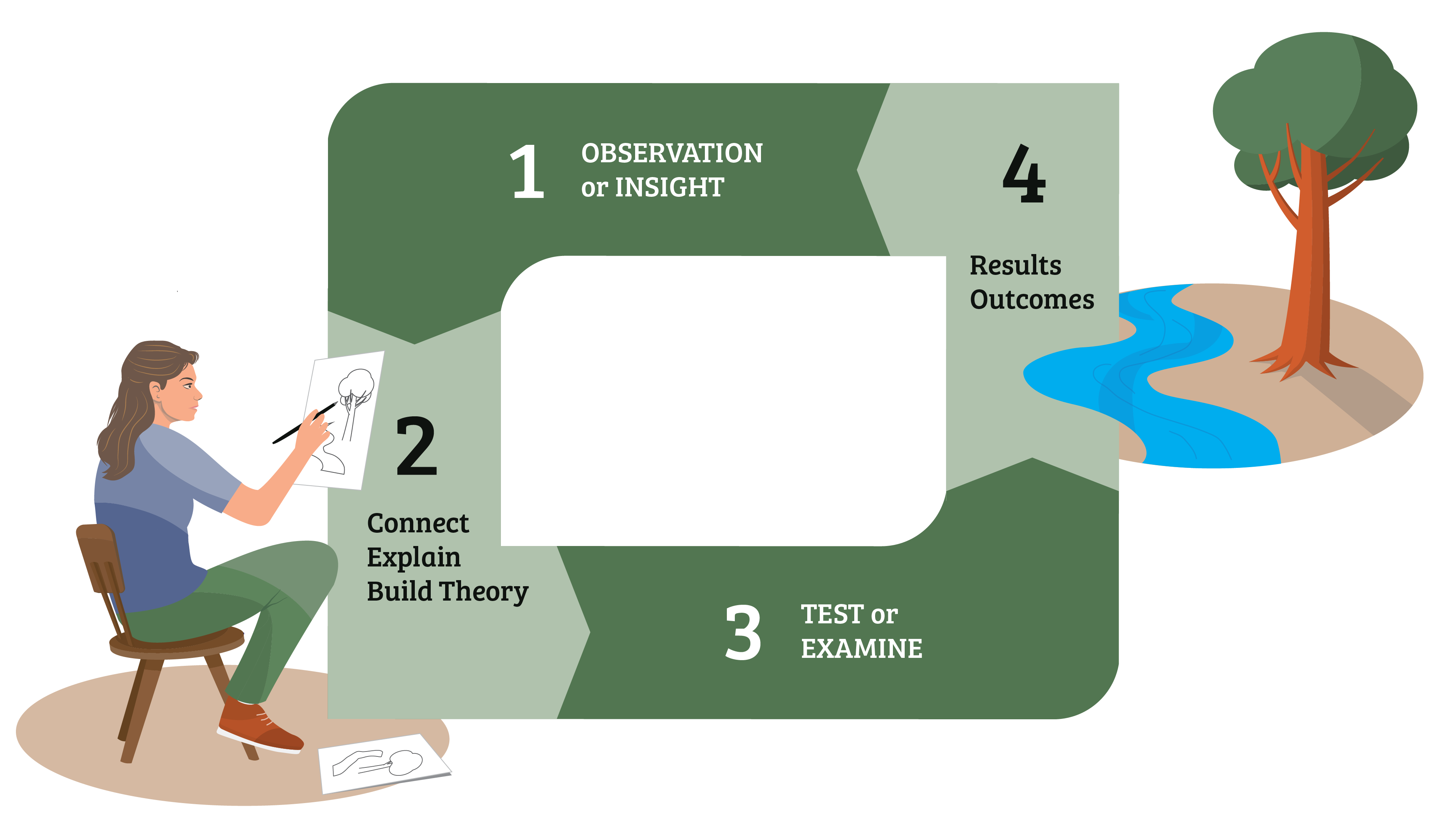
This provides us with a useful framework to check how LLMs operate, and help us decide if and when they will provide information we can trust. For this article, we will focus on three key differences.2
LLMs lack direct access to reality
The core engine that builds reliability for humans is the continual testing of our beliefs and theories against reality. This starts when we are babies and we spend our lives as toddlers tasting and banging things as a way to try to figure out how the world we found ourselves in actually works.
LLMs, however, necessarily learn differently - and an important clue is in the name. These AI systems are not trained directly on the real world. All of their training inputs are pre-existing representations of the world - originally language, but also now images and various forms of data. Humans train their understanding of what is true by spending years butting our heads and stubbing our toes against the real world (metaphorically and literally) while LLMs are trained on representations of the real world, not the world itself. Where their training is reinforced via human input, it is always based on what their programmers think they should do or think the world is like. Everything they are trained on is at least one step removed from reality.
This means that their information and reliability is of a different kind to human knowledge. An analogy, or a thought experiment, can illuminate the differences. Imagine there is a person - far into the future - who grows up on, and has never left, a spaceship but is deeply interested in forests and wildlife on Earth. Let's assume they have an amazing memory and have spent their life going through a huge library of written information, audio and video about their interests. They have access to a vast amount of information about forest and wildlife, but they have no way of genuinely experiencing what they look, feel, smell and sound like in person. How reliable is their knowledge of forests and wildlife?

So long as they stick to the information they have been directly provided, what they know will likely be highly reliable. But as soon as they try to make inferences, connections, extrapolations they will almost certainly come up with things that are a bit odd. We have all had the experience where we have read, heard or seen something and thought we understood it - but then when we actually saw or heard the thing in real life we realised that we had it very wrong. We can know a huge amount of information about something, but we will usually miss things unless we can interact with it directly.
Back to our spaceship dweller, they might be an expert on the information about forests and wildlife on Earth, but that is a different thing to being an actual expert on the forests and wildlife.
The structure of information that LLMs have and can use is very much like our spaceship dweller. They have a huge amount of information about the world, but very limited ability to access reality in any direct way. We humans can move around, pick things up, play with and experiment - all as a way to be in the world and test what we think we know. These options are not available to LLMs.
For clarity, this is a particular issue with LLMs and not necessarily with all AI or computing systems. There are situations where a computer can interact directly within a world (or reality) as well as humans can - and in those cases they often know far more or are far more effective than we are.

One good example are the programs that play games like Go or Chess. The relevant world of these games - the board and pieces - can be perfectly built in a digital world and so programs can effectively live in the worlds and complete the testing cycle depicted above. In these cases - and many computer games also qualify - computers have a decisive edge over humans. They have effectively infinite time, perfect memory, and vastly faster processing speeds than humans. So we end up learning from them, when they have direct access to the reality that matters.
Humans use models or theories of objects in the world
A second contrast between humans and AI is in the way we store and carry knowledge around. Alongside all of our factual knowledge, humans store knowledge in the form of theories or models of how the world works. An important feature of all of these theories and models is that they are dynamic or predictive. I can ask you what would happen if a particular event was to occur - it doesn't matter whether it is about economics, the state of your Grandmother's favourite vase, or your cousins' relationship with their partner - and you can provide a useful prediction. Importantly, we don't have to have seen the same situation play out in the past to be able to make good predictions. We can rely on the ways our theories or models work.
This feature of human theories and representations of the world is foundational to how we build reliability. We form expectations about what we think will happen and it is only by seeing how things play out in practice that we learn whether our theories are reliable or not. This is the core engine of the scientific method - hypothesis and experiment - just as much as it is the core engine of how we learn to cook food that tastes good.
The components of our theories or models are objects or properties of objects in the world. In science, we have theories of quantum mechanics, or of disease transmission, or of material structures. All these theories are based on how objects, or properties of objects, behave in the world. This means we can, within our theories or our minds, pick them up, turn them around, pull them apart and do various things to them - that, if it is a good theory or model, match what happens in the real world.
LLMs, on the other hand, are not trained on objects or properties of objects in the world. They are trained on text, images, number and data - and their training process involves building patterns and connections between how these are used in the body of information available online. This inevitably builds a fundamentally different type of theory. It can only be about how words, pictures and audio relate together - not how things in the real world interact. If the information that we train an LLM on is accurate, then the representations it is trained on should match the way objects in the real world interact, and there won't be big differences between the two types of theories. However, they aren't the same type of thing and differences will inevitably emerge.
One good example of a relevant difference is that LLMs are not good at spatial reasoning. If you provide an LLM with a scenario that involves objects at different places in a physical space and asking for their relationship to each other, they often struggle. As humans, we deal with these situations by building a picture in our minds (or even by drawing it) of how all the different things fit together in space. This type of reasoning is unavailable to LLMs as their training is entirely on the relationship between words and pictures, not between objects in the world.

Again, this is a feature of LLMs and the way they are programmed, rather than of all AI or computing systems. A good example of a system that explicitly builds a model of the the real world and updates it is the software automated vehicles, or driverless cars, operate on. These systems run a 3D model of the world around the car and continually update the model based on their various sensors. These systems can, and have to, predict behaviour of traffic based on their 3D models as the updates from sensors continually lag real time slightly due to the computing required to process sensor inputs. These systems have a theory or model of objects in the world in a way that LLMs do not.
What we actually say is only part of what we know and communicate
The fact that LLMs are trained on language and images - representations of the world - rather than objects or properties directly in the world, leads to a further important difference to human knowledge. We know that there is always a gap between what we say and the reality, or between a picture (or video) and what is actually there. Commonly, this is a gap in resolution or information content. Try as hard as I might like, I can never tell you exactly what my house is like, or take pictures or videos of it, that will provide you as much information as you would get if you actually visited.
As humans, we exploit this gap all the time for our own purposes. We stage photos in various ways to provide the image that we want people to see. We tell the story in a way that reflects the situation in a way that we are happy with. But, at least when we think about it, we are aware that there is a gap between the representation - the story, the picture, the theory - and the reality of what happened or what something is like.
As there are inherent limitations in language and images, our communication relies heavily on situation and context to be effective. I need only provide a partial description of my house because I know that you will recognise the right one when you are close. Pictures are often coded with a wide range of information, whether it be style, shot, what is included, and what is left out, that tell us a huge amount if we understand the context. A lot of what we communicate happens as a combination of what is said, written or shown, plus a range of background information and context.
Information online is typically created within some kind of context like this, but it is stored and preserved in a highly context-free way. Most content online is a response to something that is happening somewhere (online or real life) and is only rarely explicitly or completely referenced. We know we can assume our readers will get it when we post it. But, if you come to it later, we often have to infer the context based on what we already know about the world. This means that the training data LLMs use is made up of a vast amount of information that is disconnected from its immediate context and so cannot be easily connected to the full range of information that was originally communicated.

A nice example of this dynamic is the sentence in the image. Depending on what the question it is a response to, or on the emphasis on different words, it has seven different meanings. You can read it aloud and stress each word differently to see the range of meanings. If we came across this sentence as an isolated tweet, or as a forum post, we would obviously understand the literal meaning of the sentence, but would entirely miss the meaning implied by the stress or the context - even though that meaning might be the critical point being made.
This dynamic, where the real meaning of a statement, or image, is partially determined by the context or who said it, is very common. These aspects are only sometimes partially available in the training data for LLMs, which significantly limits the information that LLMs can absorb. Humans are almost always working with a richer and more nuanced, albeit greatly restricted in scope, set of information inputs.3
Put differently, humans tend to remember and code information with a wide range of contextual factors that play into whether we trust it or count it as knowledge. These include time, context, who said it, what it was said in response to, why someone might have said it, what we would have expected them to say and so on. These are rarely recorded in writing or images, but taken as given background context, and so this is almost all unavailable in the training data for LLMs.
Interestingly, I am not aware of any digital or AI system that functions like humans do here, even in a restricted way. I'd love to hear from readers if they have any examples of systems that do explicitly take into account and track the context around statements of information.
So when should we trust LLMs?
I started this article by considering whether, in worrying about whether we can trust the information they provide, we should think of LLMs as more like textbooks or people. Like people, LLMs apply analysis to the information they have access to and synthesise outputs. However, unlike people, they only have access to information about the world, not the world itself and rarely have access to the important context around statements or pictures that often make them highly meaningful for humans. This makes them more like textbooks. Their reasoning is, ultimately, only about the information they have about the world - they do not have models or theories of objects in the world - which limits their reliability.
To bring it all together, the reasoning involved means that, in considering reliability, LLMs do function somewhat like humans, except that we need to remember that they can only ever be experts on information about the world, not directly on the world itself. They can synthesise what the existing literature tells us, but their reliability can only be as good (at best) as the reliability of the literature they draw from. Moreover, due to the lack of context available to them, the types of information that LLMs are more reliable for are similar to textbooks or reference material, i.e. anything that is largely context-free and applicable universally. Anything that relies on local context, nuance or understanding the 'real story' is likely to be beyond what LLMs will ever be reliable on.
These claims are, I would hope, testable and I would appreciate hearing reactions. In particular, I am very interested if anyone has good ideas for tests or experiments we can run with LLMs to test whether my claims here are correct, or where they fail.
I would also be very interested in ideas of how to build systems that get around some of these limitations, if possible. I expect this will require more specialised and less universal systems than current LLMs, but am happy to be proven wrong.
There is a lot more to be said here, but I’ve left the more technical discussion out for readability and space reasons. Let me know if you want more detail.
I have written already about some others, including how they classify objects and concepts; and the assumptions underpinning their use of information.
This post has turned out to be a useful illustration of these dynamics. Regular readers will notice that I have used italics and bold to stress particular words far more often than normal - to try to make the meaning clearer.
This is very interesting for a number of reasons! It seems one more important piece of real world context that could have been discussed is the relational aspect - that as a human being I understand more about what another person is conveying through cognitive and emotional empathy as I sit with them, watch them and converse with them. There's also the very strong relational constraints the real world puts on us - we worry about being shamed in public, offending our friends, failing to love the people we should care for.
Another thing that occurred to me is how willing we are becoming to be like the machines. When we read the news, we 'experience' what is going on far from us, where the real lived experience might be a very different thing. People get so angry about the Israel-Hamas war without any personal knowledge or experience of what is going on or the history of the place, and get so angry about Donald Trump where what he is doing has very little impact on them at all. Like the LLMs, we just process second hand information and treat it like it's a real part of our lives when it isn't.
A very interesting analysis - thanks. I think it’s helpful to draw the distinction between having experience of the world and having information about the world: it highlights how different we humans are from AI. I know many people express concerns about ChatGPT and his friends going rogue and becoming motivated to achieve something beyond the specifically defined tasks assigned to them (e.g. by trying to enslave humans and take over the world). But I wonder if it’s our experience of (or at least our innate desire to engage in) tasting and banging things, butting heads and stubbing toes, picking things up, pulling them apart and playing with them that actually cause humans to want to do stuff that we’re afraid of AI doing (e.g. achieve control of things and people). In other words perhaps AI is as likely to want to achieve world domination as a library of textbooks, because they don’t experience the joys and frustrations of living in the world like humans do.